

SRE活動で成功させる
信頼性の高いアジャイル開発の手法とは?
DX全盛のいま、旧来のウォーターフォールからアジャイルへと開発手法の主流が移りつつあります。しかし、単にスピードを優先すればいいというものではありません。速さと信頼性、価値を両立させるSREの方法論を解説します。

目次
いま、なぜアジャイル開発がもてはやされているのか
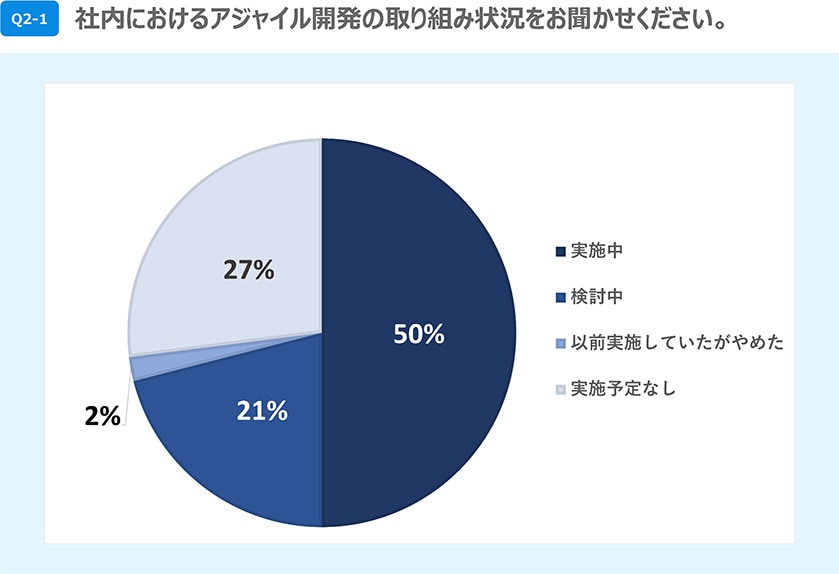
業務変革に向けたDXの取り組みをはじめ、昨今のソフトウェア開発ではスピードが最優先されます。それに伴って、開発手法も従来のウォーターフォール型では対応が困難なことから、アジャイル型への転換が求められています。経済産業省も企業のDX推進の方向性を示す「DXレポート」で、繰り返しアジャイル開発の重要性を提言しています。もはやDX推進とアジャイル開発は切っても切れない関係にあるといえそうです。その影響もあってか、ある調査によると「社内におけるアジャイル開発を実施中」の企業はすでに5割に達する勢いです。
同調査でアジャイル開発における課題について訊ねたところ、「アジャイル有識者が不足している」がもっとも多く、「大規模な案件にアジャイルを適応できない」「ミニウォーターフォール化している」という結果が続いています。いずれもアジャイルに関する知見不足から生じた課題だといえます。

こうした背景から、いま、スピーディかつ低コストにアジャイル開発で仕上げたソフトウェア・サービスの品質や価値が問われるようになっています。有識者不足などに加え、スピード、コストを重視するあまり、従業員にとって使いづらい品質・価値の低いソフトウェア・サービスに仕上がってしまうようでは本末転倒です。。このようなアジャイル開発の問題点を見直す方法論があるのをご存じでしょうか。
アジャイル開発の明確な指標、トイルを減らすSREとは?
アジャイル開発と合わせて耳にすることが多い言葉に「DevOps(デブオプス)」があります。これは、Development(開発)とOperation(運用)を組み合わせた言葉です。DevOpsでは開発部門と運用部門がチーム連携し、事業の変化に適応するスピード重視の開発部門、安全性・安定性など品質を重視する運用部門のギャップを埋められるメリットがあります。ちなみに、最近ではAIなどにビッグデータを学習させることで、IT基盤運用の自動化、効率化を図るAIOps(アイオプス:Artificial Intelligence for IT Operations)が注目されています。
DevOpsの概念を実現する方法論はGoogleが提唱する「SRE(Site Reliability Engineering)」です。日本語に訳すると「サイト信頼性エンジニアリング」となります。SREはインシデント発生を前提としてシステムを設計する「Design for Failure」に沿ったインフラ管理改善の取り組みです。
SREは、Googleが自社の検索エンジンサイト「google.com」の安定稼働を目的に行った、人手によるオンコール対応に頼らないインシデント管理の効率化・自動化に端を発しています。その名残で「サイト」という語が残っていますが、今日ではサービスの信頼性の柱となるIT環境全般=サイトと捉えるのが一般的です。SREと似た言葉に「CRE(Customer Reliability Engineering)」、顧客信頼性エンジニアリングがあります。SREがサービス中心設計、CREは顧客中心設計という信頼性を担保する対象が変わることが相違点です。
つまり、DevOpsの実現に向けてソフトウェア活用の手法を用いたチーム体制や機能、新たな運用管理プロセスがSREとなります。SREの担当者にはインフラのみを担当するインフラエンジニアの役割に加え、アプリケーションエンジニアのスキルも必要になります。このため、インフラエンジニアと一線を画すために「リライアビリティエンジニア」と呼ばれることもあるようです。
SREではサービスの信頼性、価値を向上させるため、コードによって手作業で繰り返し行われるトイル(Toil)の削減・撲滅、自動化されていない作業の一貫性の確立、ロールアウトの状況把握および迅速なロールバックの実現という課題を解決するためにリリースエンジニアリングを用います。このためにサービスの信頼性を担保する指標を決め、継続的なモニタリングがポイントとなります。
効率的にSREを進めてポストモーテムの実現へ
【ステップ1】最適なチームの編成
SREを推進する手順として最初に専任チームの編成が必要です。カギを握るのは人選で、ソフトウェアエンジニアを中心とするチームづくりが重要になります。しかし、すべてをソフトウェアエンジニアで固めてしまえばいいわけでもありません。ちなみにGoogleではSREの推進にあたり、半数は正規のソフトウェアエンジニア、残りはほかのメンバーにはない技術を持つエンジニアで構成しています。このように、多様な個性を持つエンジニア間で、チーム連携を高めていくことが成功のポイントです。
【ステップ2】実測値をもとに目標値を決める
続いて取り組むべきは、SLI(Service Level indicator)の計測にもとづくSLO(Service Level Objective)の設定です。SLIは日本語にするとサービスレベル指標、つまりサービスの状態を測るための指標になります。サービスのレイテンシー(待ち時間)、エラー率、可用性、耐久性といった具体的な数値を指定します。
SLIで算出した数値をもとに設定する目標値がSLOです。ここで重要になるのが、サービスの信頼性がどの程度損なわれても許容できるかを示す指標となるエラーバジェットです。 たとえばレイテンシーであれば5ms以内、可用性の維持であれば非稼働率を0.01%以下に抑えるといったSLIにもとづく指標がエラーバジェットになります。これによりビジネス観点のカスタマ―ジャーニーであるCUJ(クリティカルユーザージャーニー)におけるサービスに対する従業員満足度、ロイヤリティを高めていくことがポイントになります。
SLOと似た用語でSLA(Service Level Agreement)があります。ITサービスの契約時に「この稼働率を下回る場合は金銭的に補償する」ことを示す値です。SLOは補償を伴わない目標値であるためSLAとは異なります。ダイエットに例えるなら1日当たりの摂取カロリー、運動量、体重などのリアルな数値がSLI、目指す数値がSLO、目標が未達成の場合に罰金が発生する仕組みがSLAでしょうか。
【ステップ3】自動化・省力化によるトイルの削減・撲滅
続いてのプロセスが、自動化・省力化に向けたプログラミングによるトイルの削減・撲滅です。SREではサービスを構成するシステムの拡大に伴い、トイルを含む運用工数が比例して増大しないよう自分らプログラムを書いて積極的に自動化・省力化を進める必要があります。トイルの削減・撲滅により生まれるメリットとしては、個人の視点で見るとプロジェクトにかけられる時間が増大し、キャリアの形成が容易になります。組織の視点で見ると、本業である経営に資するエンジニアリングに集中していると評価されるようになります。しかし、エンジニア組織ではないと思われてしまう可能性があります。
【ステップ4】具体的な運用の改善
SREにおける運用の改善は非常に詳細かつ広範囲になるため、重要なポイントのみを解説します。
〇モニタリングの改善
担当者の解釈に依存する属人的な対応を避けるため、機械的に即座の対応が必要な「アラート」、即座の対応が不要な「チケット」、対応そのものが不要な「ロギング」という3つの指標を使ったモニタリングを実施。最適な出力方法に向けた改善を重ねます。
〇緊急対応時の手順書作成
サービスに緊急対応が必要になった場合、即興の対応ではなくなく、「あらかじめ作成された手順書通りに対応」したほうが平均修復時間に3倍の改善が見られるとGoogleは発表しています。SREチームは各サービスの綿密なトラブルシューティングのヒントとなる手順書の制作を推進する必要があります。
〇変更管理
Googleでは稼働中のシステム変更が原因で約7割のインシデントが発生しているとしています。これを防ぐために「漸進的なロールアウトの実装」「高速かつ正確な問題の検出」「問題が生じた際の安全なロールバック」の3つに取り組むことで、リリースの速度と安定性の両立が可能になります。
〇需要予測にもとづくキャパシティプランニング
サービスの今後の成長を予測し、見合ったキャパシティを確保するキャパシティプランニングは、サービスの信頼性の維持には不可欠です。さらに需要予測に基づいて必要なリソースを手配するプロビジョニング、利用率をもとに効率性の観点から判断するリソース活用の視点も必要になります。
【ステップ5】ポストモーテムの導入
ポストモーテム(Post Mortem)とは、もともとは「検死」を意味します。SREにおいては、事後検証のような意味合いで利用されます。具体的には、インシデントなどの失敗から学びを得るための定型化されたプロセスを設けることがサービスを運用するうえで必要であるという考えです。問題になったと推定されるアクションを特定し、ドキュメント化して共有します。イこれによりサービス運用の自動化を推し進め、トイルの削減・撲滅につなぐことでゼロタッチオペレーションも夢ではないでしょう。
近い将来、SREをベースとしてサービス基盤運用にバイモーダルITモデルの適用も視野に入れましょう。これは米国のIT調査会社ガートナーが提唱した考え方で、企業内のIT基盤運用の体制をモード1(守りの領域)とモード2(攻めの領域)に大別し、それぞれに適した手法で構築・運用するアプローチです。安定性と信頼性に重きを置くモード1の手法、スピード感を重視したアジャイル開発などが適用されるモード2の手法を切り分け、モード2ではSREの考え方に沿った運用モデルへの転換を図るべきです。
アジャイル有識者不足という課題を解決するには
DXを推進したい経営層に対して、DevOpsの概念を理解してもらうのは困難かもしれません。しかし、信頼性や品質を指標とする開発手法のSREであれば理解してもらえるはずです。まずはサービス運用の効率化・自動化からスタートして、徐々にサービスの信頼性、品質を高める指標に活動を拡大していくのがセオリーといえるでしょう。臨機応変にCI/CD基盤改善ツールやバージョン管理ツール、コンテナ活用などで可用性、拡張性の高いクラウドネイティブな開発環境を目指していけばいいのです。
SREの基礎知識については、おおよそ理解していただけたかと思います。とはいえ、SREチームを編成できるようなエンジニアが社内にいないという企業の方も多いのではないでしょうか。そのような有識者不足を解消し、SREを加速、支援するソリューションが各社からリリースされています。それでは、ここからはNTT Comが提供するいくつかのソリューションをご紹介したいと思います。
統合ICT運用サービス「X Managed」(クロスマネージド)は、システム運用を担うエンジニアの業務負担をトータルに軽減するソリューションです。オンプレミスとマルチクラウドのハイブリッドな基盤運用にフレキシブルに対応。さらに多彩なコンポーネントによる運用効率の向上、トラフィック分析やデータ分析などの多彩な機能によるシステム最適化とビジネスのDX推進に貢献します。
「Kompira」(コンピラ)は、ICT運用自動化、業務プロセスの無人化・自動化を実現するソリューションです。対応漏れの防止や業務効率化、運用品質の向上、稼働率や稼働人数を低減などの導入効果があります。トイルなどの定型業務の自動化からスタートし、段階的に非定型業務の自動化、より高度なインシデント対応の自動化までを実現。サービス品質改善による安定したサービス提供を実現します。
最後に紹介する「ZABICOM」(ザビコム)は、ラトビアのZabbix社がオープンソースとして供給するサーバー・ネットワーク監視システム「Zabbix」を用いたトータルソリューションです。Zabbixによる監視システムの構築から運用までをNTT Comがワンストップでサポートします。高度な監視体制の実現により、システム運用の大幅な効率化を可能にします。
どうやってSREを進めるべきかと迷ったら、あれこれ悩むより知見のある相手に相談したほうが近道です。一度、NTT Comのようなパートナーに相談してみてもいいのではないでしょうか。
X Managed®
ICTコラムお役立ち資料

