

 JP
JP




















人とAIが音楽を共同制作
約10年にわたってAIに携わってきたというシバタさん。講演冒頭ではいち早くAIに着目した理由やAIがこれまでたどってきた変遷について概要を説明しました。
シバタ:「10年ぐらい前からAIに関わってきました。みなさんにとってAIは新しいテーマなのかもしれませんが、AIがあらゆる産業で意思決定として使われるようになったのは5年前くらいからです」

「10年前、AIは『生成』ではありませんでしたが、予測や分類、推測、判別はできていました。インターネット上で扱うデータが多いGoogleやFacebook(現・Meta)がAIを使うのは当然の流れでした。それ以外にも製造業やヘルスケア業、金融などの既存産業でもAIの活用が積極的に進んでいきました」
「AIが写真や絵画みたいな画像を生成する技術が生まれた時には、自分が今まで考えていたAIの概念を覆すような『生成AI』の世界に関心を持ちました」
AIと人間が一緒に新しい物を創造しているケースも紹介。自身が関わっていた音楽のプロジェクトではAIがリズムなどを生成し、最後に人間のDJが作った音をミックスしたりする中で、AIの生成パターンが変わっていくことも体感したと振り返ります。
シバタ:「単にAIが創造しているのではなく、AIと人間が一緒に新しい物を創造できるということを体感しました。AIと人間の関わり方の未来を予見させてくれた出来事でした」
AIが賢くなる3要素
ものすごいスピードで進化し続けているAI。シバタさんは、AIの精度を高めていくためには、これまでのデータの量と質に加えて、アルゴリズムと計算量が精度向上に必要な要素だと説きます。

シバタ:「インターネットはネットで行き交うデータ量と一緒に価値を高めていったという背景があります。一昔前は『ビッグデータ』という言葉が盛んに使われ、データ量が増えると技術が向上する期待値がどんどん上がっていました」
「AIに関しては、データ量と質に加えて、アルゴリズムと計算量が増えていくことが精度向上には重要となります。アルゴリズムとは特定のアーキテクチャーを前提としたモデルのパラメーターのことを指したりもします」
「より賢いAIを作るにはデータをどういう手法でモデリングしていくかが重要です。その手法の一つとしてトランスフォーマーという方法論が2017年にGoogleのエンジニアによって提唱されました。この方法論は非常に汎用性が高く、この方法論でモデルのサイズを大きくしていくことで、精度の高いモデルが作れることがわかりました」
「ここでもう一つ重要なのが計算量です。特にGPUと言われるAIの計算をするのに適した処理装置を使い、大量のデータを巨大なモデルに学習させることで精度が高まります。基本的には学習させる時間が長いほどモデルの精度が高くなっていくこともわかってきました」
AIが賢くなる3要素
- データ(量×質)
- アルゴリズム
- 計算量
クリエイティブ業界でも「AI」vs,「人間」
シバタさんは昨今のAIビジネスでの動きについてNetflixを事例に挙げました。
2009年にAIが出始めた頃、Netflixは「AIを使って面白い映画をおすすめするアルゴリズムを書いてください」というコンペを実施し、勝者には1億円の小切手が贈られたことが話題になったといいます。

シバタ:「Netflixは既存コンテンツをおすすめして、多くの人に鑑賞してもらうビジネスモデルでした。でも、中毒性の高いコンテンツを制作するほうが売り上げが上がることを見いだしました」
「オリジナルコンテンツを安価で作るためにAIを利用することが非常にメイクセンスになっています」
ことしに入り、ハリウッドで脚本家らによるストライキが発生。脚本家らは「AIではなく脚本家を雇え」と強く訴えたといいます。
シバタ:「クリエイティブ業界でもAI対人間のような構造が生まれています。これまではAIに置き換わる仕事はもっと簡単で単純作業だと思われていました。しかし、今ではクリエイティブな仕事にもAIが影響を及ぼす時代になっています」

ChatGPTの欠点
シバタさんは生成AI「ChatGPT」の欠点に関して指摘しました。
欠点としてファクトベースでの返答や記憶をしないことなどが挙げられるようです。

シバタ:「ChatGPTの可能性に期待している人たちは多いと思いますが、いくつか欠点もあります。ChatGPTは2021年9月までの情報は知っていますが、その先の情報は知らない。事実が違う間違ったことをあたかも本当のように表現してきます」
「記憶もしてくれません。私が2日前に尋ねたことは覚えていません。毎回、思い出させてあげないといけません。今、尋ねたことに対して返してくれるだけなので、自発的に何か提案するという行為もありません」
「去年、Googleのエンジニアが生成AIが感情を持ったみたいな話もしています。今世の中に出回っているサービスは感情をあまり表現しないようにチューニングされているように思います」
「これらの課題は今後、急速に解決されていくでしょう」

生成AIと関わる3つのポイント
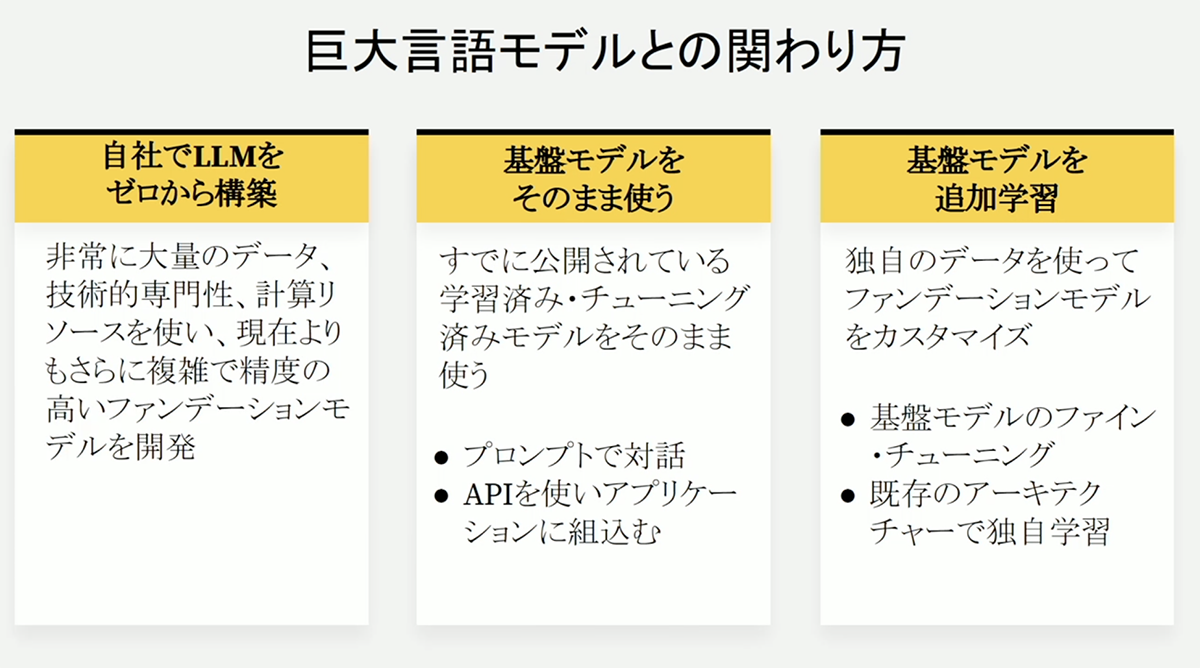
シバタさんは今現在、生成AIとの3つの関わり方を紹介。
①LLMをゼロから構築②基盤モデルをそのまま使用③基盤モデルを追加学習、が挙げられるといいます。
その中でもLLM構築をゼロから構築するのはコストや時間がかかり、専門性も高いといいます。
中小企業などの会社がすぐに活用できるのは、基盤モデルの使用やそれを追加学習させることから始めることがおすすめのようです。
LLM(Large Language Model: 大規模言語モデル)。
人工知能の一種であり、電子的な“脳みそ”とも呼ばれている。LLMが大量のテキストデータを学習することで、人が話す言語の文法や意味を把握し、それをもとにテキストの生成や解釈ができる。
シバタ:「多くの方々がやっているのは基盤モデルの利用だと思います」
「例えば、基盤モデルの『ChatGPT』と対話の中で、プロンプト(ChatGPTに対して質問をする時の文章)に工夫を重ねて、より自分が求める有用な答えが返ってくることなどはわかりやすい事例と言えます」
追加学習でカスタマイズ
シバタさんは基盤モデルに追加学習をさせ、カスタマイズする事例を紹介。基盤モデルが思い通りに反応してくれるようになります。
シバタ:「例えば会社に大量のデータがあります。前提としてテキスト型のデータとしましょう」
「それはChatGPTが知らない情報です。それをどうやってChatGPTに知ったように答えさせるのか。大量のデータも含めて返答をしてもらうよう追加学習ができます」
「データを検索するだけでしたら、ChatGPTは要りません。こういうことを加味して答えてくださいと指示して返ってくるような仕組みです」

シバタさんは会社のマニュアルを具体例に挙げて、追加学習の効果を説明しました。
シバタ:「具体的な例としてはマニュアルがたくさんある会社があったとします。多くの機械に関する使い方のマニュアルがあって、特定の機械の使い方を教えて欲しいという時に、誰かに聞けたらいいですよね」
「『工作機械を後ろ向きに動かしたいんだけど、どのボタン押せばいいんですか』と尋ねたとします」
「『〇〇マニュアルの237ページの下から2行目に書いてあります』と説明されるよりも、聞いた答えに瞬時に答えてほしい」
「追加学習させた大量のマニュアルから、後ろ向きに動かすための情報を抽出し、コンテキストをプロンプトで作ることもできます」

求められるAIの専門家
ChatGPTなどの生成AIが仕事にも浸透していく中で、視聴者からは「AIの専門家人材を社内でどう育てているのか」といった質問も寄せられました。
AI人材を社内でどう育成していくかとの問いに対して、シバタさんはオンラインで精度の高い情報に触れていくことから始められると説きました。

シバタ:「AIに関する情報はオンライン上でたくさん公開されています。コンサルティング会社が提供しているものや書籍も多く世の中に出回っています」
「オンライン上でも英語の文献やレポートが山ほどあります。私がよくやる方法ですが、ChatGPTに英語の文章を翻訳させて読むという方法です」
翻訳精度が高いといわれているChatGPT。それをうまく利用して世界中の文献やコンテンツを読むことが最初の一歩だと説明しました。

この記事はドコモビジネスとNewsPicksが共同で運営するメディアサービスNewsPicks +dより転載しております。
文:比嘉太一
撮影:鈴木愛子
デザイン:山口言悟(Gengo Design Studio)
編集:野上英文





