JP
JP
















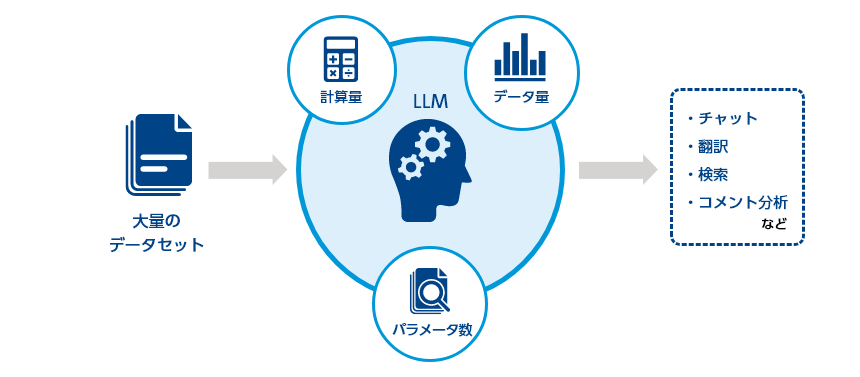
「大規模言語モデル(Large Language Models、LLM)」は「言語モデル」の一種で、コンピューターによる「計算量」、学習に使用される「データ量」、モデルの複雑さを示す「パラメータ数」の3要素を大規模化したものです。「言語モデル」は私達が日常生活の中で使っている言語(自然言語)をコンピューターが理解するために数値化するモデルですが、大規模言語モデルでは大規模化により従来の言語モデルとは比較にならない性能を発揮しています。
大規模言語モデルの始祖は2018年にGoogle社が発表した「BERT(Bidirectional Encoder Representations from Transformers、トランスフォーマーによる双方向エンコーダー表現)」といわれています。これまでは文頭から文末に向かって行っていた学習を、文末から文頭に向かって行う学習を加えて双方向で実行することにより、自然言語処理の性能が向上しました。BERT以降もOpenAI社の「GPT(Generative Pre-trained Transformer)」などのモデルが続々と登場しました。
大規模言語モデルは「基盤モデル」と呼ばれることもあります。特定の用途に向けたものではなく汎用のモデルのため、用途に応じてチャットや翻訳、検索、コメント分析などさまざまな分野に活用することが可能です。
具体的な活用例としてはチャットでの質問に答えるテキスト生成AI「ChatGPT」、チャットによりリアルタイムで適切な検索結果を表示するMicrosoft社の検索エンジン「Copilot」などがあります。
このように私達の生活にとって有益な大規模言語モデルですが、現在消費電力量が課題となっています。計算量、データ量、パラメータ数の大規模化は直接消費電力量の増加につながり、しかも性能向上とともにさらに増加しつつあります。
例えばChatGPTなどに使用されている大規模言語モデルであるGPTのパラメータ数は、2019年の「GPT-2」で約15億、2020年の「GPT-3」で約1750億と対数的に増加しました。一説にはGPT-3の1回の学習には約1300MWhと、原発1基が1時間に発電する電力量1000MWhを超える電力が必要だといわれています。続く「GPT-4」のパラメータ数は公開されていませんが、大規模化はさらに加速していると推測されます。
そのため、現在では学習データの質と量を向上させることでパラメータ数を数十億程度に抑えたNTTの「tsuzumi」など、より効率的な次世代の大規模言語モデルの開発も進んでいます。